
Créer des pipelines fiables avec Lakeflow Declarative Pipelines et Unity Catalog
Chez Barracuda, notre équipe en charge de la plateforme de données d'entreprise se concentre sur la fourniture de pipelines de données de haute qualité et fiables, permettant aux analystes et aux dirigeants de prendre des décisions éclairées. Pour mener cette initiative, nous avons adopté Databricks Lakeflow Declarative Pipelines (anciennement DLT) et Unity Catalog pour gérer nos flux de travail ETL, garantir la qualité des données et assurer une gouvernance fiable.
Lakeflow Declarative Pipelines nous a permis d'exploiter les données d'utilisation de nos clients pour créer des applications qui aident les équipes chargées des renouvellements et de la réussite client à offrir une meilleure expérience client. Nous avons également utilisé Lakeflow Declarative Pipelines et Unity Catalog pour créer des tableaux de bord destinés à nos équipes de direction, leur permettant ainsi d'exploiter des données provenant de diverses sources afin de prendre des décisions financières plus éclairées. Ces cas d'utilisation reposent sur des données hautement disponibles et précises, pour lesquelles Lakeflow Declarative Pipelines ont apporté un soutien significatif.
Pourquoi les pipelines déclaratifs Lakeflow ?
Le cadre de transformation déclaratif principal de Databricks, incarné dans Lakeflow Declarative Pipelines, nous permet de définir les transformations de données et les contraintes de qualité. Cela réduit considérablement la surcharge opérationnelle liée à la gestion de tâches ETL complexes et améliore l'observabilité de nos flux de données. Nous n'avons plus besoin d'écrire du code impératif pour orchestrer les tâches ; au lieu de cela, nous définissons ce que doit faire le pipeline, et Lakeflow Declarative Pipelines s'occupe du reste. Cela a rendu nos pipelines plus faciles à développer, à comprendre et à gérer.
Du traitement par lots au streaming
Lakeflow Declarative Pipelines offre des fonctionnalités fiables pour optimiser le traitement incrémentiel des données et accroître l'efficacité des flux de travail de gestion des données. En utilisant des outils tels qu'Auto Loader, qui traite de manière incrémentielle les nouveaux fichiers de données à mesure qu'ils arrivent dans le stockage cloud, notre équipe de données peut facilement gérer les données entrantes. L'inférence de schéma et les indications de schéma simplifient davantage le processus en gérant l'évolution du schéma et en garantissant la compatibilité avec les jeux de données entrants.
Voici comment nous définissons une table d'ingestion de streaming à l'aide d'Auto Loader. Cet exemple montre les options de configuration avancées pour les indications de schéma et les paramètres de remplissage, mais pour de nombreux pipelines, l'inférence de schéma intégrée et les valeurs par défaut suffisent pour démarrer rapidement.

Une autre fonctionnalité très utile que nous avons adoptée est la prise en charge par Lakeflow Declarative Pipelines de la capture automatique des données modifiées (CDC) à l'aide de l'instruction APPLY CHANGES INTO. Pour les données stockées dans des systèmes tels que S3, le traitement incrémentiel devient transparent. Cette approche permet d’éliminer la complexité de la gestion des insertions, des mises à jour et des suppressions. Cela garantit également que nos tableaux en aval restent synchronisés avec les systèmes sources tout en préservant la précision historique en cas de besoin, en particulier lorsque vous utilisez des outils tels que Fivetran qui diffuse des flux CDC. Ces capacités garantissent que les pipelines de données sont non seulement précis et fiables, mais aussi très adaptables aux environnements de données dynamiques.
Vous trouverez ci-dessous un exemple de configuration SCD1 plus avancée, utilisant notre table bronze comme source, avec fusion de schémas et filtrage de colonnes personnalisé.


Garantir la qualité des données en fonction des attentes
Les attentes de Lakeflow Declarative Pipelines nous permettent de tester la qualité de nos données en définissant des contraintes déclaratives qui valident les données à mesure qu'elles transitent par le pipeline. Nous définissons ces attentes sous forme d'expressions SQL booléennes et les appliquons à chaque jeu de données que nous ingérons. Afin de rationaliser la gestion des règles, nous avons développé un cadre personnalisé qui charge les attentes à partir de fichiers JSON, ce qui facilite la réutilisation des règles dans les pipelines tout en conservant la clarté du code.
Il s'agit d'une implémentation avancée qui fonctionne bien à notre échelle, mais de nombreuses équipes pourraient commencer par quelques instructions en ligne et évoluer au fil du temps. Ci-dessous, nous montrons comment nous structurons les attentes JSON et les appliquons dynamiquement lors de l'exécution du pipeline.

Amélioration des tables de quarantaine à l'aide de fonctions définies par l'utilisateur (UDF)
Bien que Lakeflow mette automatiquement en quarantaine les enregistrements non valides en fonction des attentes, nous avons étendu cette fonctionnalité avec une fonction définie par l'utilisateur (UDF) personnalisée afin d'identifier les règles spécifiques enfreintes par chaque enregistrement. Cette approche ajoute une colonne « data_quality » à nos tables mises en quarantaine, ce qui facilite le traçage et le débogage des problèmes de données.
Cette personnalisation n'est pas requise pour les flux de travail de quarantaine de base, mais elle permet à notre équipe de mieux comprendre pourquoi les enregistrements échouent et permet de hiérarchiser les mesures correctives de manière plus efficace. Ci-dessous, vous trouverez la manière dont nous avons mis en œuvre cette amélioration à l'aide de nos règles d'attente prédéfinies.

Surveillance et gouvernance de la qualité des données avec Lakeflow Declarative Pipelines + Unity Catalog
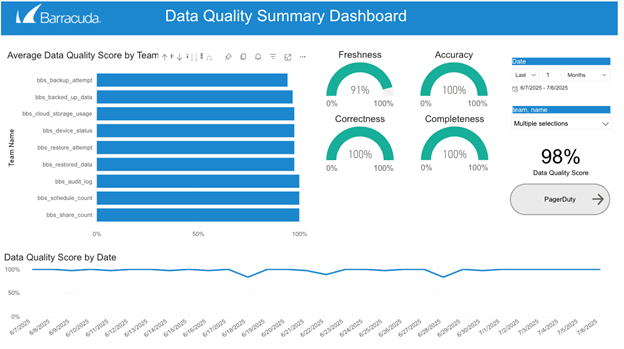
Lakeflow Declarative Pipelines capture automatiquement les événements d'exécution détaillés grâce à son journal d'événements intégré, y compris les validations de règles, les enregistrements mis en quarantaine et le comportement d'exécution du pipeline. En interrogeant ce journal, nous sommes en mesure de générer des indicateurs complets de la qualité des données, de surveiller l'état de plus de 100 jeux de données et de détecter de manière proactive les problèmes avant qu'ils n'aient un impact sur les utilisateurs en aval.
Nous avons renforcé cette base en mettant en place des alertes en temps réel qui nous informent lorsque les données ne répondent pas aux attentes prédéfinies ou commencent à s'écarter des modèles normaux attendus. Ces alertes permettent à notre équipe d’enquêter rapidement sur les anomalies et de prendre des mesures correctives.
Unity Catalog complète cela avec une gouvernance centralisée, un contrôle d’accès précis et une traçabilité complète des données. Ce cadre combiné renforce la confiance dans nos données, garantit une application cohérente des politiques de qualité et d'accès, et nous offre une visibilité claire sur l'état et l'évolution des actifs liés à nos données.
Bonnes pratiques et enseignements tirés en matière sécurité
La mise en œuvre de Lakeflow Declarative Pipelines s'accompagne de contraintes uniques et de fonctionnalités évolutives qui améliorent la convivialité pour les développeurs et rationalisent les opérations. Au départ, certaines restrictions, telles que l'exigence de sources en ajout seul et d'une seule cible par pipeline, ont représenté des défis. Cependant, l'exploitation de fonctionnalités telles que les indications de schéma et la possibilité de lire d'autres tables dans Lakeflow Declarative Pipelines à l'aide de `spark.readTable` a considérablement amélioré la flexibilité. De plus, nous avons tiré un immense bénéfice des fonctionnalités de qualité des données de Lakeflow Declarative Pipeline. Nous avons mis en place plus de 1 000 contraintes de qualité des données sur plus de 100 tableaux. Nous effectuons également des contrôles de qualité des données sur chaque tableau de notre espace de travail Databricks. Cela facilite grandement le travail de nos analystes, car ils sont en mesure de trouver, d’utiliser, de comprendre et de faire confiance aux données de notre plateforme.
Outre la qualité et la gouvernance des données, il existe plusieurs avantages mesurables en aval pour l’entreprise. L'utilisation de Lakeflow Declarative Pipelines a permis de réduire sensiblement le temps de développement et d'accélérer la vitesse de livraison, tout en minimisant les frais de maintenance et en améliorant l'efficacité de l'équipe. Par exemple, les pipelines développés avec Lakeflow Declarative Pipelines nécessitent généralement 50 % de lignes de code en moins que les pipelines déclaratifs autres que Lakeflow, ce qui rationalise à la fois le développement et la maintenance continue. Cette efficacité s'est traduite par des temps de mise en route plus rapides des pipelines et un soutien plus fiable pour les besoins commerciaux en évolution. La fiabilité des données s'est également améliorée, ce qui nous permet de répondre à de multiples cas d'utilisation en aval, tels que notre tableau de bord First Value et nos tableaux de bord d'analyse de l'utilisation par les clients, dans divers domaines d'activité.
L'introduction de Lakeflow Pipelines IDE, qui nous permet de générer des transformations sous forme de fichiers SQL et Python et d'accéder à l'aperçu des données, aux indicateurs de performance du pipeline et au graphique du pipeline (le tout dans une seule vue), a encore accru la vitesse de développement. La migration de HMS vers Unity Catalog a encore affiné ce processus, offrant une meilleure visibilité pendant l'exécution du pipeline. À mesure que Lakeflow Declarative Pipelines continue de se perfectionner, il sera essentiel d'adopter ces meilleures pratiques et de tirer parti des enseignements acquis afin d'optimiser à la fois la qualité des données et l'efficacité opérationnelle sur l'ensemble de notre plateforme.
Remarque : Sanchitha Sunil et Grizel Lopez ont co-écrit cet article de blog.





S’abonner au blog de Barracuda.
Inscrivez-vous pour recevoir des informations sur les menaces, des commentaires sur le secteur et bien plus encore.
